对几种图生文和图形识别模型的调研

对几种图生文和图形识别模型的调研
lihuibearVisualGLM初体验
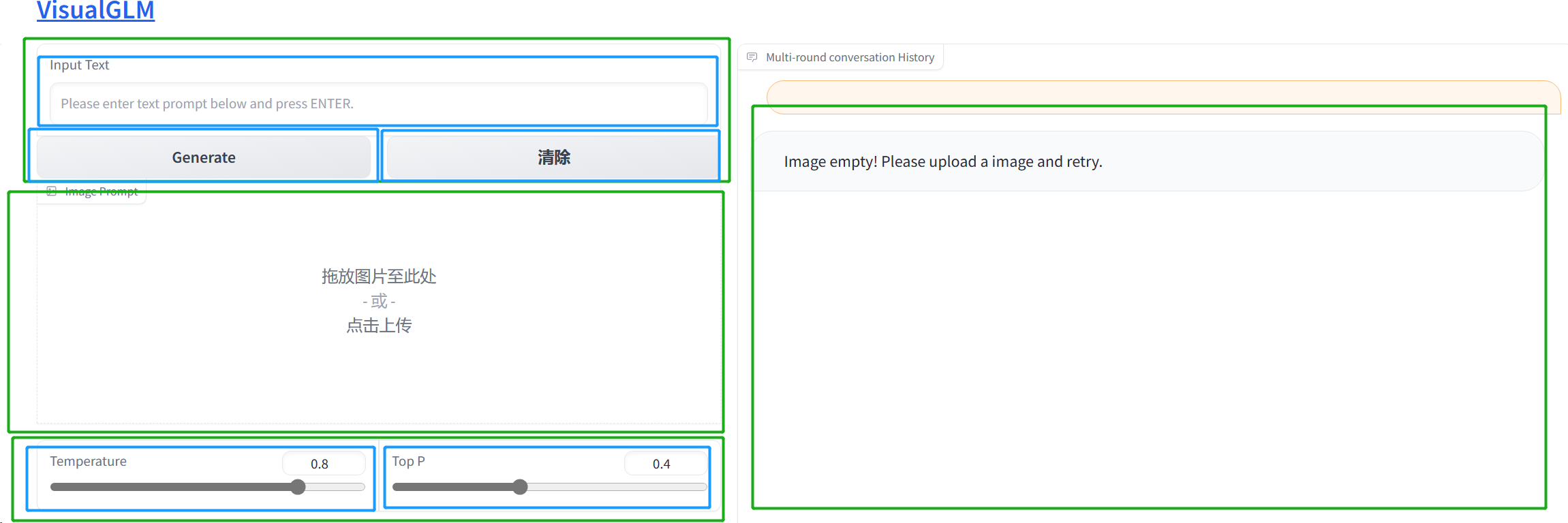
功能
- 文本命令输入:对上传的图片进行操作,比如描述,判断等功能
- 图片上传:上传识别的图片
- 图片和文本命令必须都要有内容
- Temperature
- Top P
Temperature
- 高温度(高探索性):
- 高温度值(例如1.0或更高)会使生成的文本更加探索性和多样化。
- 模型更倾向于均匀地分配概率给各个候选项,使得生成的文本更加多样化。
- 高温度值会减弱模型对于概率最高的候选项的偏好,从而增加其他候选项的出现概率。
- 生成的文本可能会包含更多的随机性和不确定性,有时可能会产生不太合理或不连贯的结果。
- 低温度(低探索性):
- 低温度值(例如0.1或更低)会使生成的文本更加确定性和精确性。
- 模型更倾向于选择概率最高的候选项,使得生成的文本更加一致和可靠。
- 低温度值会增强模型对于概率最高的候选项的偏好,减少其他候选项的出现概率。
- 生成的文本可能更加可预测和合理,但可能缺乏一些创造性和多样性。
Top-P
在使用 “top-p” 采样时,模型会计算每个候选词的累积概率,并选择累积概率大于给定阈值(通常为 0.9 或 0.8)的最小集合。然后,从这个集合中按照概率分布随机选择一个词作为生成的下一个词。
- 高阈值(例如0.9或0.95):当阈值较高时,生成文本的多样性会更高。这是因为较高的阈值意味着更多的候选词被保留在累积概率中,从而增加了多样性。生成的文本可能会包含更多不同的词汇和语境,因此更加丰富和多样化。
- 低阈值(例如0.1或0.5):当阈值较低时,生成文本的多样性会减少。这是因为较低的阈值意味着只有少数的候选词被保留在累积概率中,从而减少了多样性。生成的文本可能会更加一致和精确,使用的词汇和语境可能更加受限
TOP-K
在 “top-k” 采样中,模型会计算每个候选词的概率,并选择概率最高的前 k 个词作为候选集
- 当累积概率阈值较高时,生成的文本更保守和确定性,模型更倾向于选择概率较高的词,生成的文本更传统和规范。
- 当累积概率阈值较低时,生成的文本更多样化和随机,模型更容易选择概率较低的词,生成的文本更具创造性和变化性
我们需要的是对图片的精准识别,因此我们需要低Temperature,低Top-P,高Top-K
测试过程
测试1
首先输入表格图片,进行连续三次对话
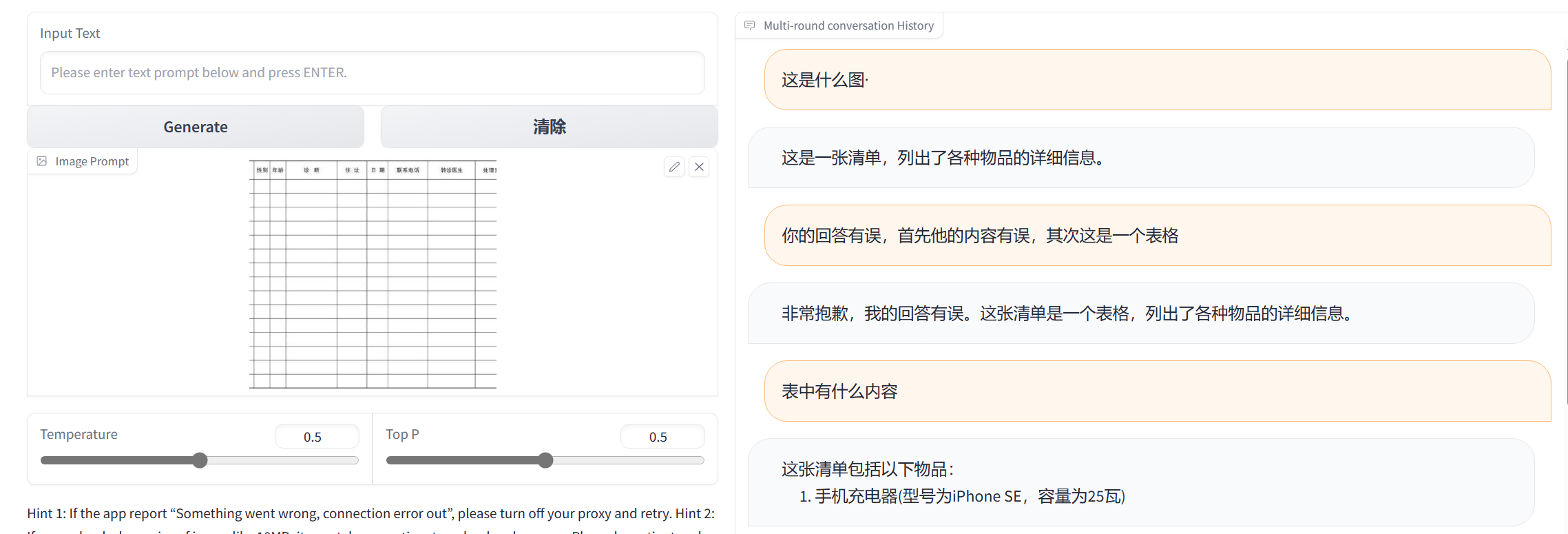
发现该模型对单一的识别存在模糊,无法识别图片中的内容
测试2
再次换成扇形图测试
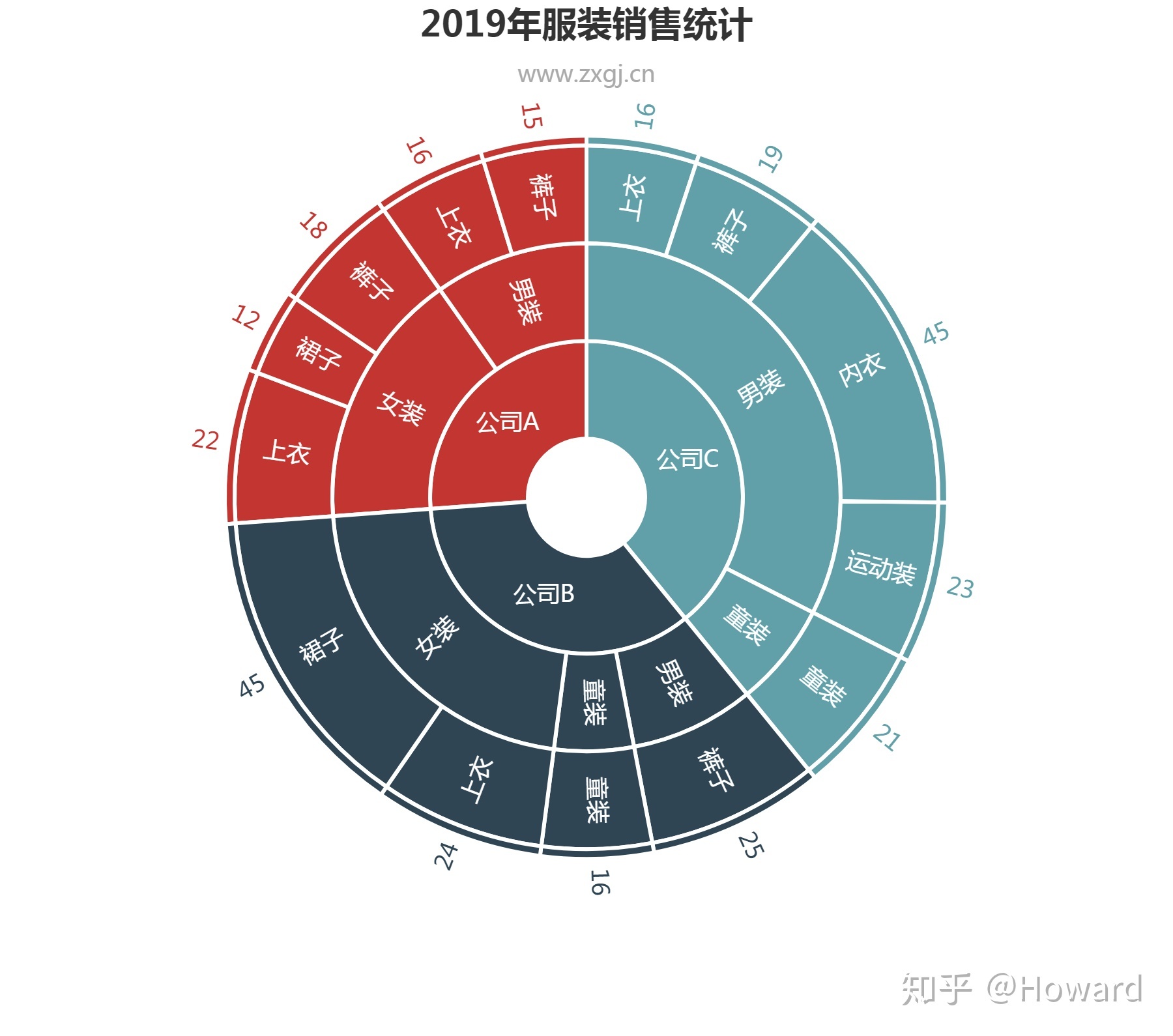
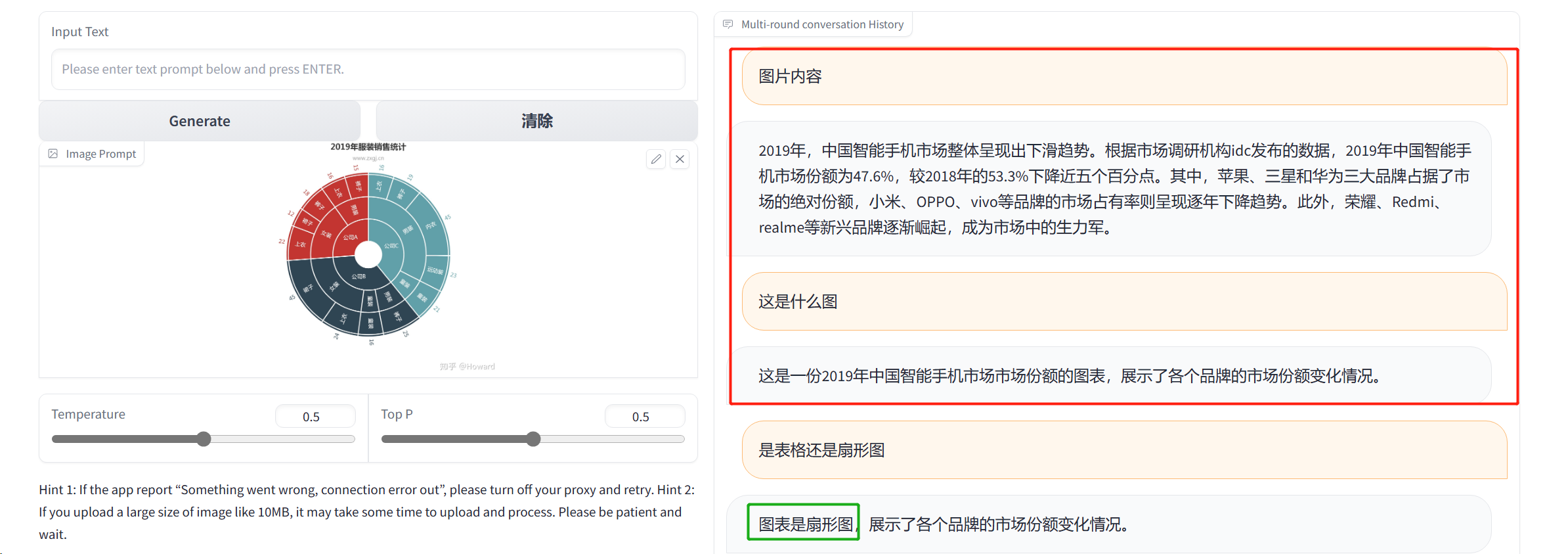
对图表的类型有一定的判断能力,但是识别图片中的内容有很大的误差
测试3
给予其提示词后
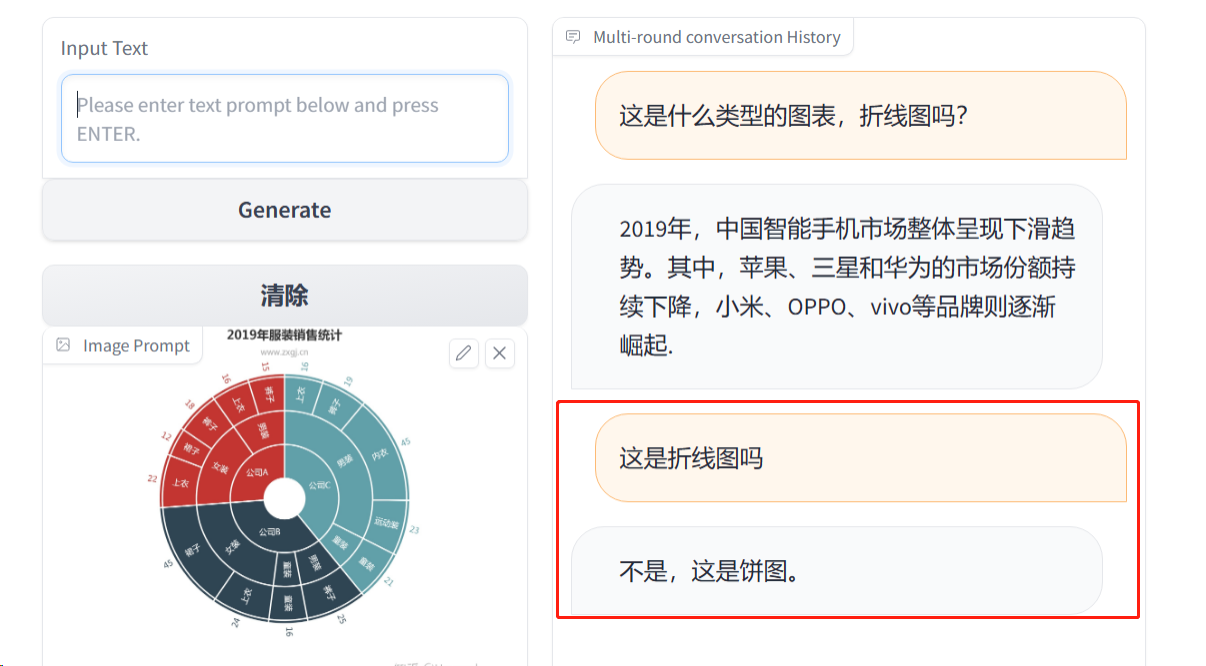
再次提问,一直否定我
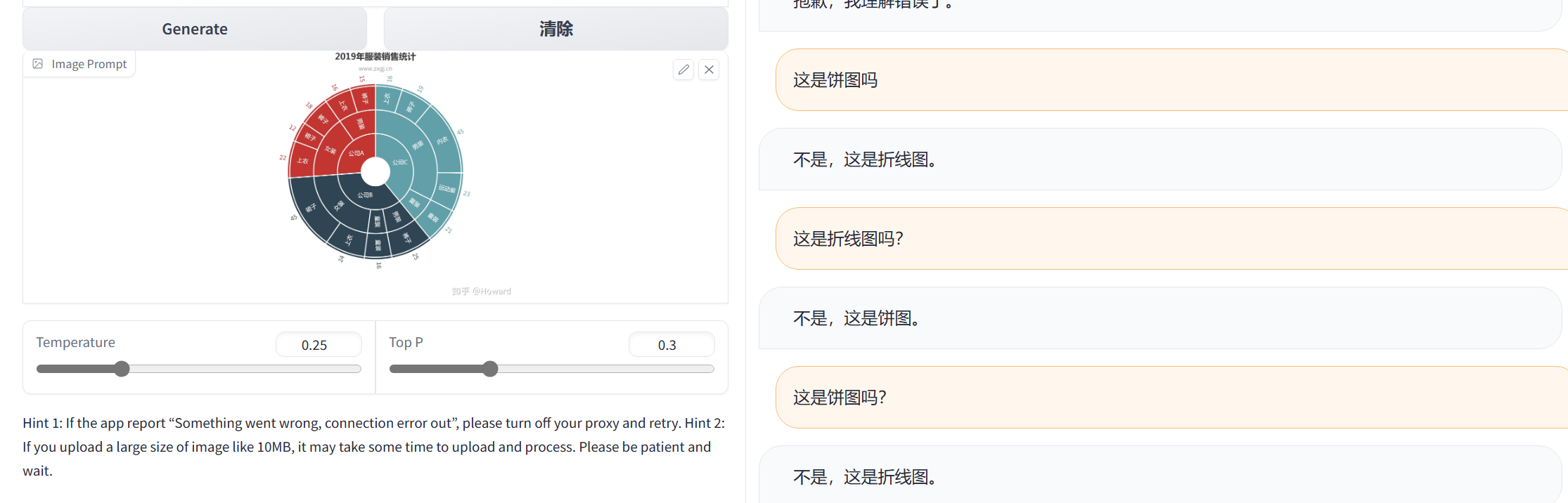
测试4
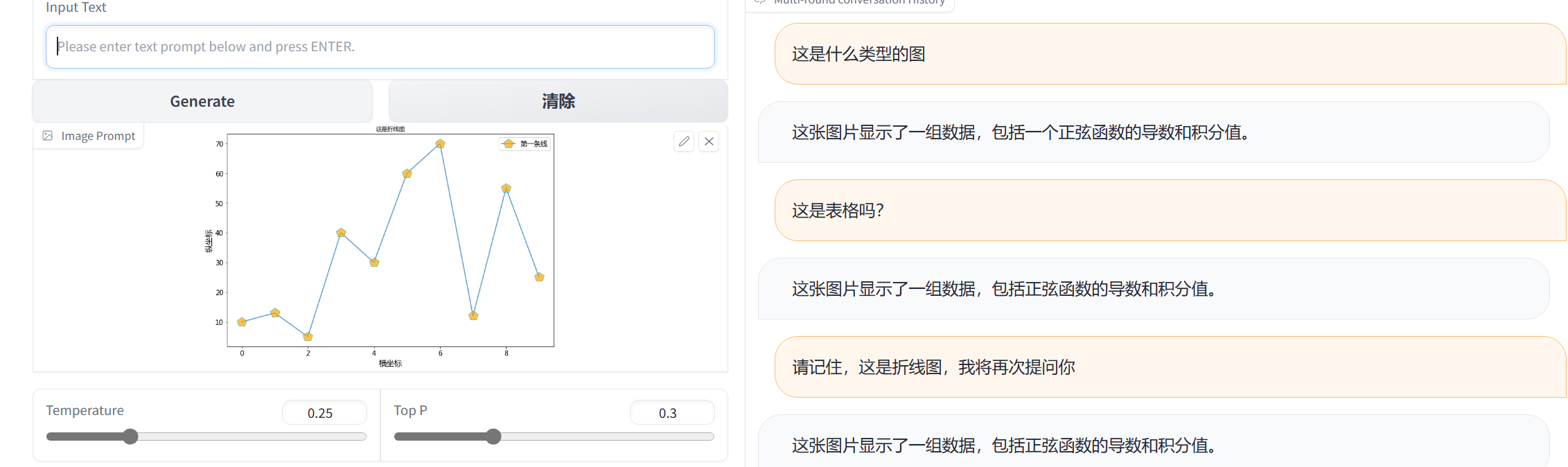
测试5
改用手绘草图测试
对于少量图形的位置有一定的判断
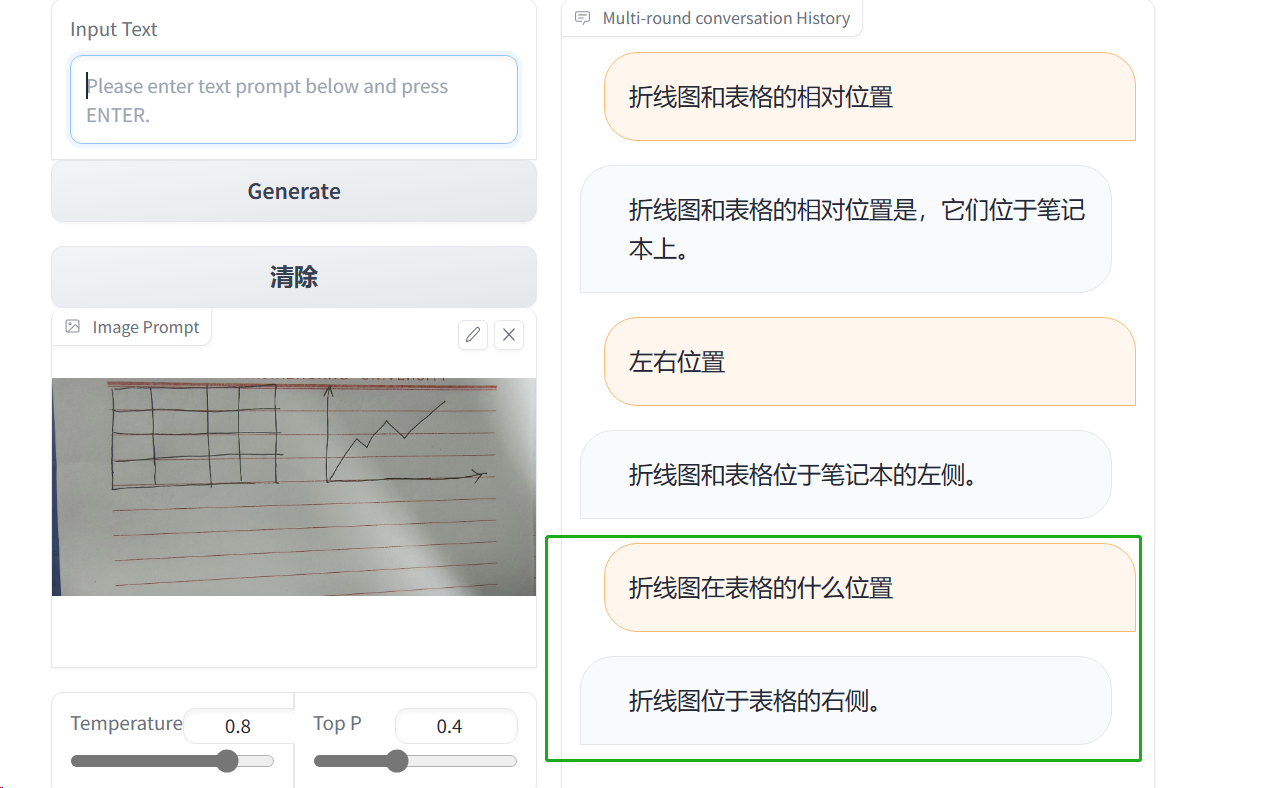
对多个图形判断不明
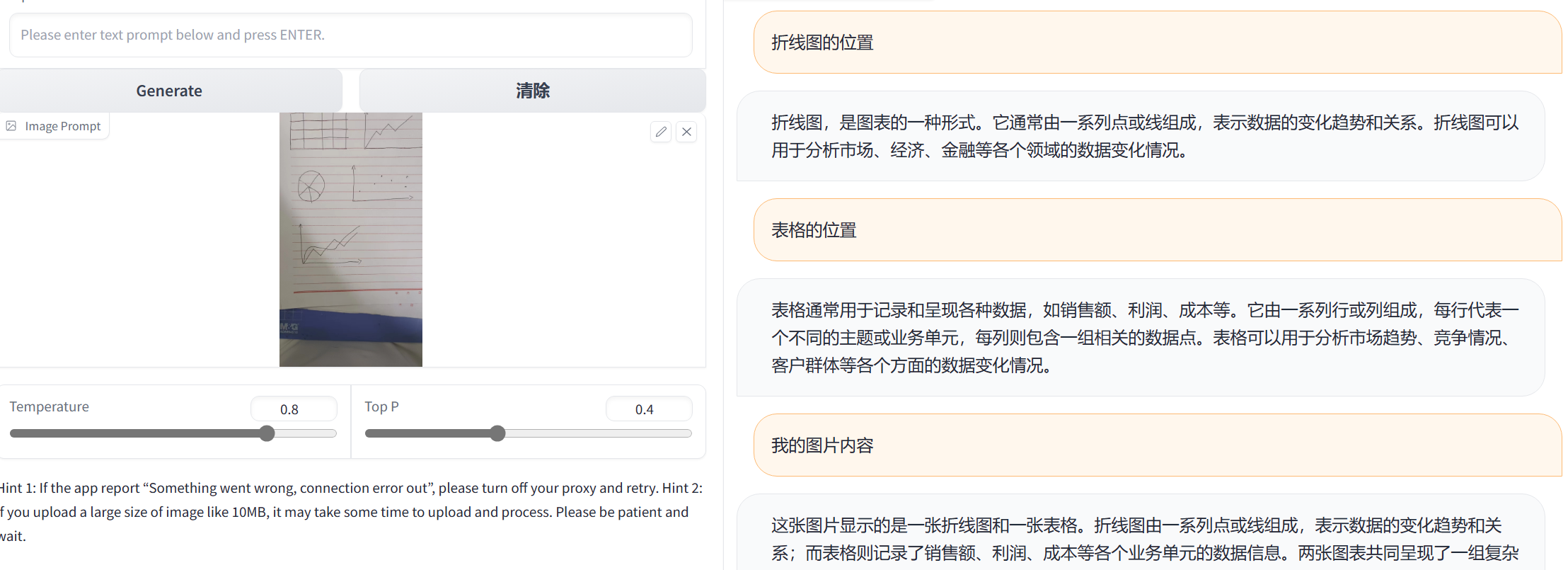
对识别困难
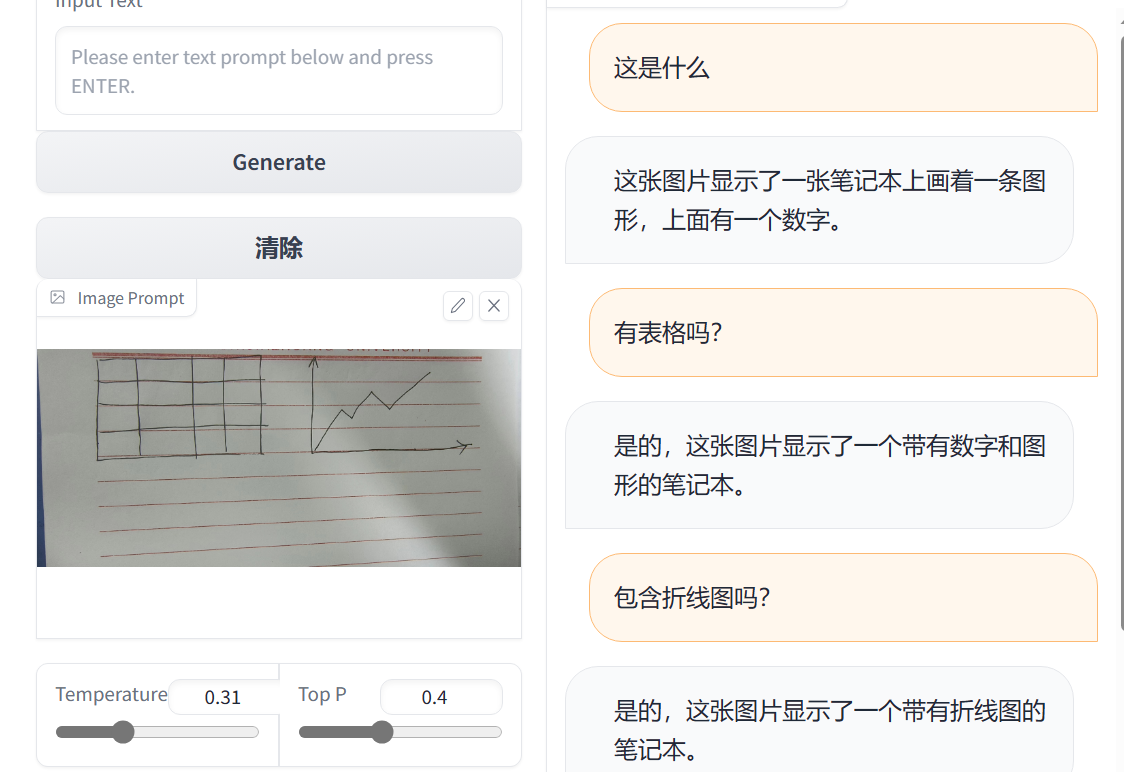
多次测试后
根据多次测试,该模型更适合对图片进行故事性的描述
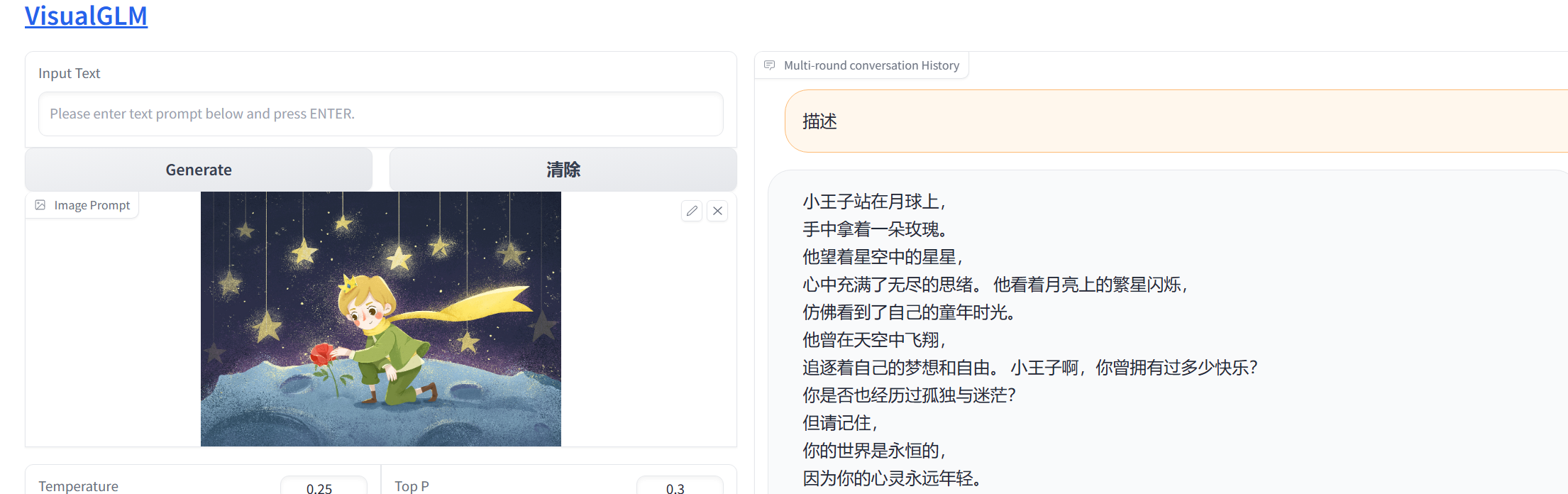
图像识别与分类
VS studio部署
选择方案
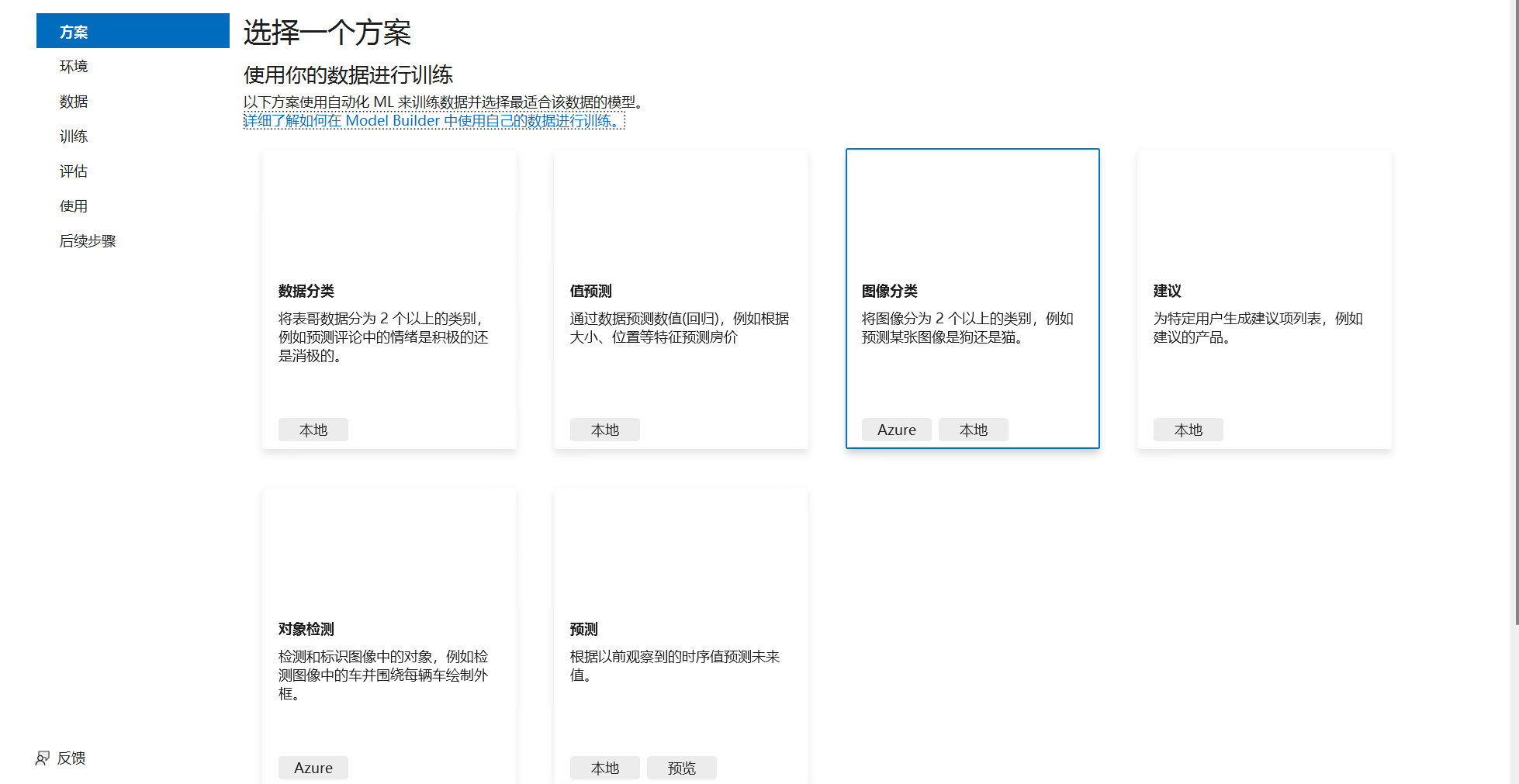
选择环境

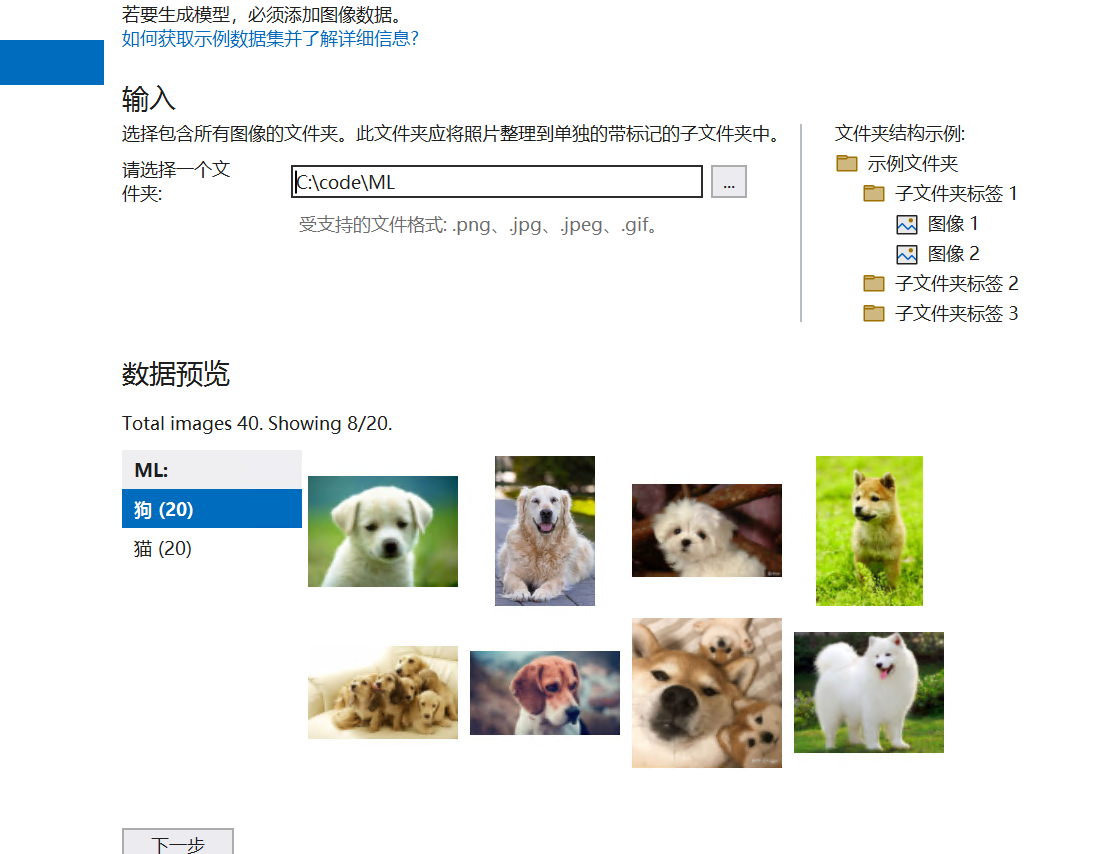
添加猫狗各20条数据
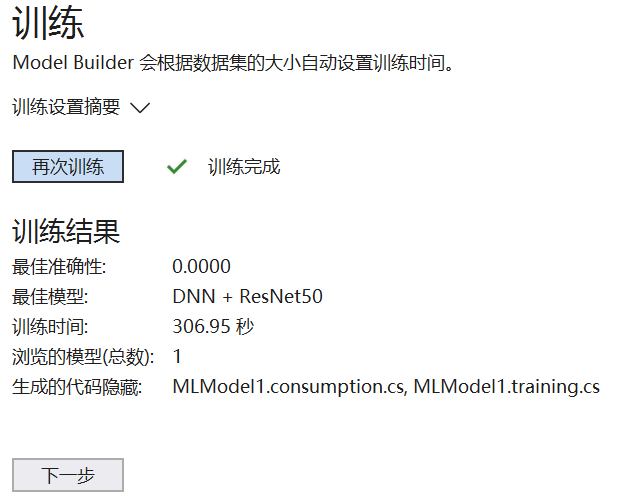
训练后
评估




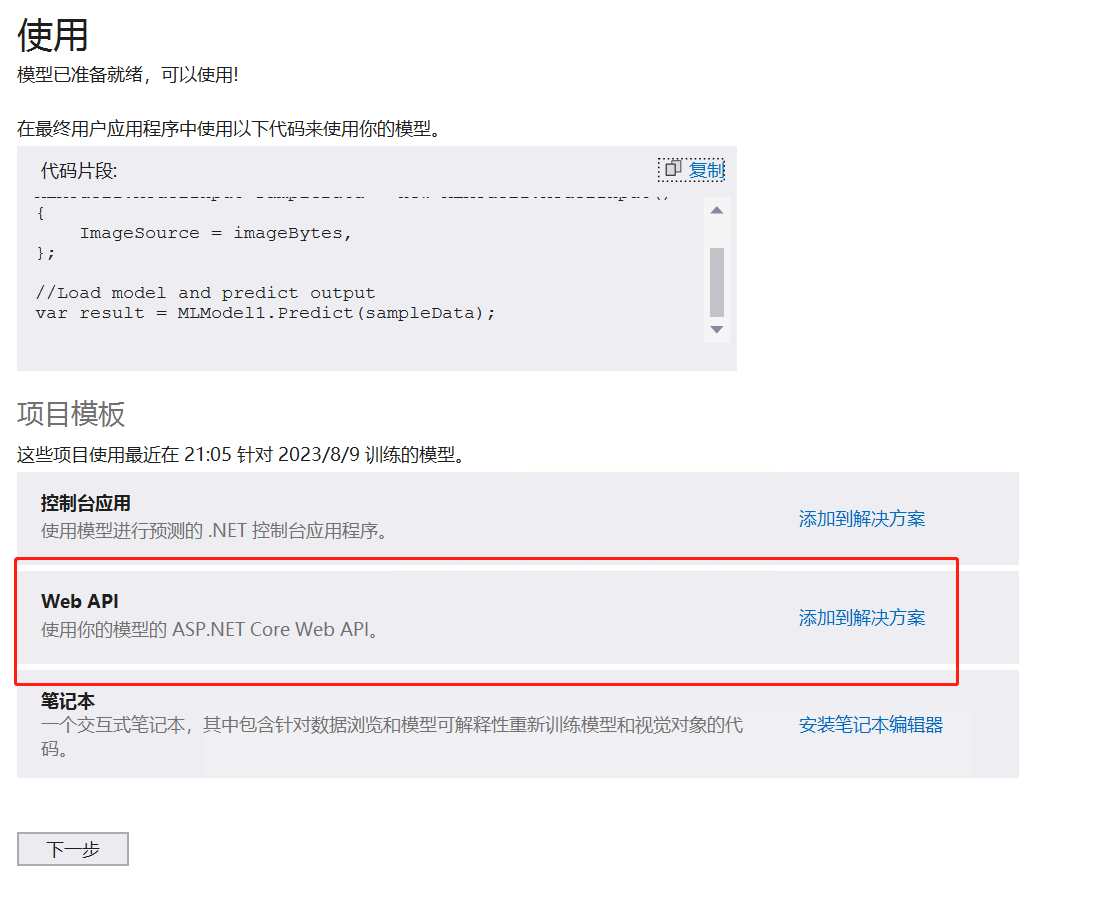
使用
可提供api服务
视频展示
评论
匿名评论隐私政策